La compresión de datos es una verdadera ciencia dentro de otra. La idea fundamental es muy simple, guardar la mayor cantidad de datos posibles en la menor cantidad de espacio posible. Los algoritmos de compresión a lo largo de la historia fueron progresando comprimiendo cada vez mas. Hoy en día coexisten algoritmos muy simples, otros muy complejos, algunos muy extraños y otros muy ingeniosos. Este capítulo revisa casi todos los algoritmos de compresión existentes y como veremos el mundo esta lleno de sorpresas.
Conceptos de Compresión de Datos
La idea fundamental de la compresión de datos es reducir el tamaño de los archivos de forma tal que estos ocupen menos espacio y que dado el archivo comprimido pueda recuperarse el archivo original (simple!)
La compresión de datos esta sólidamente fundamentada en toda la teoría que antes desarrolláramos: Para la compresión de datos la fuente es el archivo a comprimir y los mensajes son los caracteres que componen el archivo. La idea de la compresión de datos es, dado un archivo, representar a los caracteres mas probables con menos bits que los caracteres menos probables de forma tal que la longitud promedio del archivo comprimido sea menor a la del archivo original.
Debemos distinguir compresión de compactación, la compactación se refiere a técnicas destructivas, es decir que una vez compactado un archivo se pierde información y no puede recuperarse el original, la compactación se puede aplicar a imágenes o sonido para las cuales la perdida de fidelidad puede llegar a justificarse por el nivel de compresión.
Teorema fundamental de la compresión de datos.
"No existe un algoritmo que sea capaz de comprimir cualquier conjunto de datos"
Técnicamente:
"Si un compresor comprime un conjunto de datos en un factor F entonces necesariamente expande a algún otro conjunto de datos en un factor MAYOR que F"
Demostración:
Supongamos un conjunto de N caracteres y supongamos también que a todos los caracteres los representamos por códigos de igual longitud entonces:
Ln=log2(N)
Veamos si se cumple la desigualdad de Kraft.
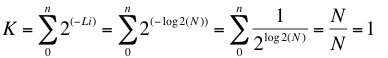
Fijemos las longitudes log2(N) para 254 de nuestros 256 caracteres: L2..L255 y supongamos que L0 se codifica con una longitud menor dejando libre L1 para ver que pasa.
Supongamos ahora que nuestro compresor comprime al caracter L0 en "D" bits.
L0=log2(N)-D
Suponiendo que los caracteres L2..L255 se codifican con la misma longitud de antes, queremos ver cual será la longitud de L1.
Li = log2(N) para 2<=i<N
Buscamos el L1 mínimo:

Por la desigualdad de Kraft sabemos que K<=1.
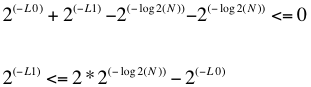

Entonces:

De aquí se deduce:
1) D<=1 con lo cual observamos que si solo se cambia la longitud de dos códigos entonces las longitudes cambian a lo sumo un bit.
2) Si D=1 entonces E>= !!!
3) Si D=0 entonces E>0 en general E=c(D)*D con c(D)>1
por ejemplo si D=0.5
E>=0.77155
De aquí se demuestra que si achicamos L0 en 0.5 bits debemos agrandar L1 en 0.77155 bits, lo cual demuestra el teorema.
Si todos los caracteres son equiprobables comprimir uno de ellos implica expandir el archivo.
El teorema puede 'mostrarse' en una forma menos técnica razonando de la siguiente manera: Si un algoritmo comprime 'cualquier' archivo entonces comprime a todos los archivos de 'n' bits. Supongamos que los comprime solo un bit (lo mínimo que le podemos pedir). Hay 2N archivos de N bits y 2N-1 archivos de N-1 bits, por lo tanto habrá por lo menos 2 archivos de N bits que se comprimieron generando el MISMO archivo de N-1 bits, por que resulta imposible recuperar el archivo original a partir del comprimido.
El razonamiento es claro pero sin embargo ...
El episodio del Datafile/16.
En abril de 1992 WEB technologies de Smyrna anuncia el desarrollo de un programa que comprimiría a cualquier archivo de mas de 64Kb a un dieciseisavo de su longitud original (en promedio), WEB no solo proclamaba eso sino también que el algoritmo podía ser aplicado en forma recursiva a archivos ya comprimidos por él mismo con idéntico resultado. El revuelo causado entre los neófitos por tal anuncio fue de tal magnitud que el newsgroup sobre compresión de datos se vio sobresaturado de mensajes sobre el famoso programa, infructuosos fueron los intentos de los entendidos en explicar que tal cosa no era posible, la gente quería tener ese programa!
En Junio de 1992 WEB vuelve al ataque anunciando que prácticamente cualquier cantidad de bytes podían ser comprimidos en 1Kb aplicando el algoritmo recursivamente, el ingenio incluso ya tiene un nombre: Datafile/16.
Esto esta tomado textualmente de un texto de WEB technologies:
"DataFiles/16 will compress all types of binary files to approximately one-sixteenth of their original size ... regardless of the type of file (word processing document, spreadsheet file, image file, executable file, etc.), NO DATA WILL BE LOST by DataFiles/16. Performed on a 386/25 machine, the program can complete a compression/decompression cycle on one megabyte of data in less than thirty seconds"
"The compressed output file created by DataFiles/16 can be used as the input file to subsequent executions of the program. This feature of the utility is known as recursive or iterative compression, and will enable you to compress your data files to a tiny fraction of the original size. In fact, virtually any amount of computer data can be compressed to under 1024 bytes using DataFiles/16 to compress its own output files muliple times. Then, by repeating in reverse the steps taken to perform the recusive compression, all original data can be decompressed to its original form without the loss of a single bit. Convenient, single floppy DATA TRANSPORTATION"
El 28 de Junio Earl Bradley de WEB technologies anuncia un importante acuerdo con una empresa de Sillicon Valley a la cual se le vendería el algoritmo.
WEB continua tirando pistas durante Junio, anuncian que el código ocupa 4K y que solo usa aritmética entera y un buffer de 65Kb.
Mientras el compresor no aparecía las sospechas se hacían mayores, pero la gran mayoría de los usuarios realmente creía que el producto existía,
ante reiterados pedidos WEB insistía en que el acuerdo con Sillicon Valley le impedía lanzar inmediatamente el producto.
El 10 de Julio de 1992 WEB realiza uno de los anuncios mas cómicos en la historia de la computación, leer para creer:
“El equipo de testeo ha descubierto un nuevo problema en el cual cuatro números en una matriz implicaban un mismo valor. Los programadores se encuentran trabajando en un preprocesador para eliminar este raro caso."
El 3 de agosto de 1992 WEB anuncia que sus programadores fueron incapaces de resolver el susodicho problema y que el proyecto se cancelaba. La conclusión que debemos obtener de esto es que no existen los milagros, no se puede ir en contra de las propiedades demostradas matemáticamente y no es posible comprimir cualquier conjunto de datos. El texto es anecdótico y resulta cómico pero millones de personas fueron engañadas durante mucho tiempo. (Y alguna empresa de Sillicon Valley también).