Discos Sectorizados: Son aquellos en los cuales cada pista del disco se divide en un cierto número de sectores de n bytes cada uno. Los sectores están predefinidos por el fabricante del disco y se podrían ver como “repositorios” en donde el programador almacenará la información de los archivos. La capacidad de almacenamiento de un disco de estas características se define como:
Capacidad = QSectores · LSector
¿IRGS?
IRGs en discos sectorizados: En discos sectorizados los IRGS existen como separación entre sectores, pero no son considerados en absoluto por el programador pues sabiendo la longitud de un sector y el número de sectores por pista LP se calcula como:
LP = Lsector x Sects-pista
Y en este caso TODOS los bytes de la pista están disponibles para almacenar datos. El programador se desentiende de los IRGs.
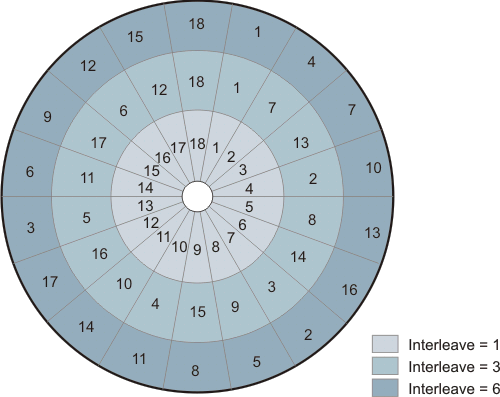
Interleave
Ubicación de los sectores en la pista: Intuitivamente una forma lógica de ubicar los sectores en la pista es numerarlos en forma correlativa, el sector 1 en cualquier lugar, luego el dos, a continuación el tres y así sucesivamente, esta disposición sin embargo tiene un problema. Debido a que el IRG entre sectores es muy pequeño era frecuente que una vez leído un sector el disco ya hubiera girado lo suficiente como para que el sector dos ya hubiera pasado por delante de la cabeza lectora-grabadora. Luego era necesario esperar casi una vuelta entera del disco para poder acceder al sector dos. Como puede verse esta situación dista mucho de ser conveniente. Para solucionar este problema se recurrió al llamado "Interleave factor". Lo que se hizo fue separar los sectores de forma tal de que dos sectores correlativos pudieran leerse uno a continuación de otro, el espacio entre sectores se llenaba precisamente con otros sectores, la distancia entre dos sectores se llama Interleave factor. Cuanto más rápido se pueda leer un sector menos interleave será necesario. Hoy en día la mayoría de los discos trabaja con interleave 1, es decir, un sector a continuación del otro.
Por ejemplo con interleave = 3 en un disco con 18 sectores por pista la pista se vería de la forma:
1 7 13 2 8 14 3 9 15 4 10 16 5 11 17 6 12 18
(entiéndase que por ser la pista circular luego del sector 18 viene el 1,7,13 etc.) Como puede verse la distancia entre dos sectores correlativos es 3.
Clusters
En general el tamaño de un sector es fijo para una unidad de discos en particular, y suele ser un tamaño no muy grande, por ejemplo 512 bytes. Si se tuviera que acceder al disco cada 512 bytes, el número de accesos sería muy elevado y los tiempos de lectura y grabación muy altos. La mayoría de los sistemas operativos arreglan este problema mediante el uso de clusters. Un cluster es un conjunto de sectores que pueden ser leídos con un único acceso. Para el programador el cluster es la unidad mínima de transferencia. Todo archivo ocupa por lo menos 1 cluster aunque en realidad sólo tenga un byte.
La cantidad de sectores por cluster determina la cantidad de clusters por pista y siempre son números enteros.
Extents
Si vamos más allá con la agrupación lógica de sectores para formar estructuras más grandes podemos hablar de los extents. Si tuviésemos todo el disco a nuestra disposición para almacenar información y necesitaramos grabar un archivo en él, lo ideal sería guardarlo usando sectores contiguos para de esa forma facilitar el acceso al mismo evitando pérdidas de tiempo por Tseek y Tsearch. Si este fuese el caso, diríamos que el archivo fue almacenado en un solo extent, es decir, en un único espacio contiguo de almacenamiento dentro del disco. Si luego quisiéramos agregarle más información a dicho archivo y no pudiésemos usar los sectores lindantes al fin del archivo (porque están usados por otros archivos, por ejemplo), entonces deberíamos reservar un nuevo extent de n sectores para almacenar la nueva información. En este caso tendríamos un archivo formado por un extent inicial y por un extent secundario. Así podríamos ir agregando extents a este mismo archivo cada vez que fuese necesario.
Sectores Spanned vs. no Spanned
A la hora de almacenar los registros que conforman un archivo dentro del disco sectorizado se presentan dos alternativas. Supongamos que tenemos un tamaño de registro de 350 bytes y que el tamaño de un sector es de 512 bytes. Claramente se observa que luego de que almacenamos un registro dentro del sector no tenemos espacio suficiente como para almacenar otro registro completo en ese sector. Y acá es donde se presentan las dos alternativas que mencionamos recién.
1) Podemos almacenar el siguiente registro en un nuevo sector. Esto presenta la clara desventaja de que estamos desperdiciando 162 bytes por sector en nuestro ejemplo, ya que de los 512 bytes disponibles solo usamos 350 bytes que es lo que ocupa un registro. La ventaja que podemos ver en este caso sería el hecho de que para acceder a un registro determinado solo necesitaríamos levantar del disco un sector, ya que estamos seguros de que el registro no se “esparcirá” entre sectores. Esta alternativa de almacenamiento se denomina NO SPANNED ya que la información almacenada en el disco no se esparce entre sectores.
2) La otra alternativa es almacenar el siguiente registro a continuación del primero, usando los 162 bytes del sector inicial más 188 bytes de un segundo sector para completar los 350 bytes de nuestro registro. De esta forma no estamos desperdiciando espacio ya que aprovechamos el 100% del tamaño de cada sector para almacenar información de nuestro archivo. La contra sería que en este caso para acceder a la información del segundo registro deberíamos leer tanto el primer sector como el segundo. Esta forma de almacenamiento se denomina SPANNED pues los bytes que conforman la información del archivo se ubican uno detrás del otro ocupando todo el espacio disponible en los sectores en que se divide el disco.
Es esta última la forma en que el sistema operativo MS-DOS y las diversas versiones de Windows gestionan el almacenamiento en disco, por lo que será la alternativa que trataremos en más detalle a continuación.