Introducción
La tecnología actual, y principalmente la informática, ha contribuido de forma única a la resolución de millones de problemas en diferentes ámbitos y disciplinas, constituyendo hoy en día el motor de procesamiento y fuente de recursos absolutamente imprescindible.
Desde sus orígenes, la informática ha visto la luz de su evolución en las actividades científicas, más precisamente en sus necesidades de almacenamiento y procesamiento de datos. Y si bien en la mayoría de los casos la ciencia y otra variedad de disciplinas han visto satisfechos sus requerimientos, aún quedan desafíos abordables que esperan a ser atendidos. Un claro ejemplo es la capacidad de procesamiento requerida en ambiciosos proyectos de investigación científica, simulaciones a gran escala, toma de decisiones a partir de grandes volúmenes de información y cientos de casos imaginables que no encuentran una solución, o quizá parte de ella, en las herramientas disponibles en la tecnología actual. En estos casos, ni aún la supercomputadora más sofisticada disponible en el mercado podría satisfacer la capacidad de procesamiento necesaria en casos donde el volumen de datos manipulado es de varios petabytes. Si bien un gran acercamiento a la resolución de estos problemas de enorme potencia de cálculo fue logrado mediante “clusters” o “granjas” de computadoras, surgidos a principios de los 80, aún seguían conservándose los recursos en forma dedicada. Existen también otras situaciones en que no sólo se persigue gran procesamiento, sino que también se busca lograr niveles de conectividad y cooperación entre proyectos científicos y académicos de gran escala que no han podido lograrse ni siquiera mediante Internet.
Muchas aplicaciones difundidas a través de Internet han ofrecido un modo más descentralizado para lograr gran potencia de cálculo gracias al aprovechamiento del tiempo de CPU inactiva aportado por sus usuarios, pero a pesar de este avance de importancia revolucionaria existen objetivos más abarcativos de conectividad entre proyectos que se ven limitados en la red de redes. En realidad, el e-mail y la World Wide Web proveen modos básicos de trabajo conjunto pero no se ha logrado vincular y compartir datos, computadores, sensores y demás recursos creando una entidad virtual. Es entonces aquí donde surge el concepto de “computación grid”(En castellano: rejilla, tramado, entrelazado, enrejado).
Varios conceptos similares coexisten acerca de qué es un grid. Uno de ellos, elaborado por el Grid Computing Information Centre, una de las asociaciones dedicada exclusivamente al desarrollo de esta tecnología, llama grid a un “tipo de sistema paralelo y distribuido que permite compartir, seleccionar y reunir recursos ‘autónomos’ geográficamente distribuidos en forma dinámica y en tiempo de ejecución, dependiendo de su disponibilidad, capacidad, desempeño, costo y calidad de servicio requerida por sus usuarios”. Según esta definición, se busca aprovechar la sinergia que surge de la cooperación entre recursos computacionales y proveerlos como servicios.
Otra definición más estructurada expuesta por Foster, Kesselman y Tuecke, precursores de la computación grid, plantea la existencia de organizaciones virtuales (OV) como puntos de partida de este enfoque. Una organización virtual es “un conjunto de individuos y/o instituciones definida por reglas que controlan el modo en que comparten sus recursos”. Básicamente, son organizaciones unidas para lograr objetivos comunes. Ejemplos de OVs podrían ser proveedores de servicios de aplicaciones o almacenamiento, equipos de trabajo empresarial realizando análisis y planeamiento estratégico, miembros de una planta de energía evaluando trabajo de campo, universidades involucradas en un proyecto de investigación conjunto, etc. Las OVs varían enormemente en cuanto a sus objetivos, alcance, tamaño, duración, estructura, comunidad y sociología. Sin embargo, existen varios requerimientos y problemas subyacentes tales como la necesidad de relaciones flexibles para compartir recursos, niveles de control complejos y precisos, variedad de recursos compartidos (programas, archivos, datos, sensores y redes, entre otros), modos de funcionamiento (individual, multiusuario), calidad de servicio, etc. Las tecnologías actuales o bien no proveen espacio para la variedad de recursos involucrados o no aportan la flexibilidad y control de las relaciones cooperativas necesarias para establecer las OVs.
Como solución, se propone el grid como un modelo de trabajo para “compartir recursos en forma coordinada y resolver problemas en organizaciones virtuales multi-institucionales de forma dinámica”. De esta manera, varias instituciones pueden formar distintas OVs e incluso formar parte de más de una al mismo tiempo, realizando diferentes roles e integrando distintos recursos como se muestra en la Figura 1.
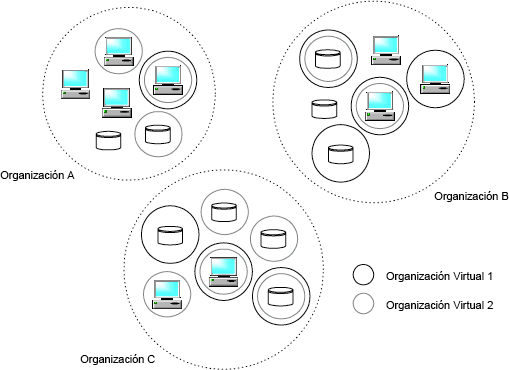
Figura 1. Una organización real puede participar en una o más OVs compartiendo algunos o todos sus recursos. Se muestran tres organizaciones reales (los círculos de puntos) y dos OVs (conformadas por los recursos compartidos en cada caso). Las políticas que controlan el acceso a los recursos varían de acuerdo a las organizaciones reales, los recursos y las OVs involucradas. Nótese que existen recursos que componen una o más OVs y otros que no se comparten.
Para lograr este nuevo cometido, se han desarrollado varios protocolos, servicios y herramientas que intentan sustentar organizaciones virtuales escalables. Debido a su enfoque basado en compartir recursos de manera dinámica y multi-organizacional, las tecnologías grid se complementan en vez de competir con las tecnologías de computación distribuida existentes.
Definiciones
Sharing
El sharing de los recursos es condicional: cada dueño de los recursos hace disponible el mismo sujeto a condiciones de cuándo, dónde, y qué es lo que puede realizarse. Los consumidores de recursos pueden colocar condiciones en propiedades de los recursos para los cuales ellos están preparados para trabajar.
Las relaciones de sharing pueden variar dinámicamente sobre el tiempo en términos de recursos involucrados, la naturaleza de los accesos permitidos y los participantes que tienen accesos permitidos. Estas no son a menudo simplemente de tipo cliente-servidor, por peer to peer: los proveedores pueden ser clientes y las relaciones de sharing pueden existir sobre un subconjunto de participantes. Además pueden combinarse de forma coordinada sobre muchos recursos, cada uno perteneciente a diferentes organizaciones. La habilidad de delegar en vías controladas se torna importante en algunas situaciones como hacer mecanismos para coordinar operaciones a través de múltiples recursos.
Un mismo recurso puede usarse de diversas formas dependiendo de las restricciones situadas en el lugar desde donde se comparten y sus objetivos. Por ejemplo una computadora puede usarse solamente para correr piezas de software específicas en un arreglo de sharing mientras que éste puede proveer ciclos genéricos de operación en otra.
En el contexto de una red la interoperabilidad se refiere a protocolos comunes. Nuestra Arquitectura Grid es primeramente una arquitectura de protocolos que definen los mecanismos básicos para cada usuario de las OV y la negociación de recursos, establecimiento, manejo y la utilización de las relaciones de sharing. La arquitectura basada en estándares facilita la extensibilidad, interoperabilidad, portabilidad y el sharing de código; los protocolos estándares hacen más fácil definir servicios estándares que provean capacidades. Se pueden construir interfases de aplicaciones para programación y kits de desarrollo de software que provean abstracciones de programación requeridas para crear una Grid usable.
A través de la interoperabilidad se asegura que las relaciones de sharing puedan iniciarse en partes arbitrarias, acomodándose dinámicamente a nuevos participantes sobre diferentes plataformas, lenguajes y entornos de desarrollo.
La definición de un protocolo especifica cómo los elementos distribuidos de sistemas interactúan en orden de devolver un comportamiento específico y la estructura del intercambio de información durante su interacción.
Las OV tienden a fluir y se notan ciertos cambios: los mecanismos usados localizan recursos y se establecen y reconocen identidades, por ello la determinación de autorizaciones e iniciación del sharing debe ser flexible y liviano de forma que el arreglo de sharing de recursos pueda establecerse y cambiarse fácilmente.
Servicios
Un servicio se define por el protocolo con el que habla y el comportamiento que implementa. La definición de servicio estándar (de acceso a computación, datos, descubrimiento de recursos, replicación de datos y más) nos permite mejorar los servicios ofrecidos a participantes de las OV y también abstraer de detalles específicos de los recursos que de otra forma deberían ser posteriores al desarrollo de aplicaciones para OV.