Discutiremos a continuación cómo lograr un mecanismo que posibilite las RPCs basándonos en la implementación esquematizada en la Fig.1. En esta figura, la llamada remota toma 10 pasos, en el primero de los cuales el programa cliente (o procedimiento) llama al procedimiento stub enlazado en su propio espacio de direcciones. Los parámetros pueden pasarse de la manera usual y hasta aquí el cliente no nota nada inusual en esta llamada ya que es una llamada local normal.
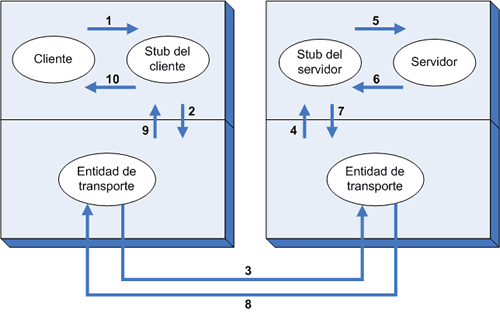
Fig. 1. Los diez pasos necesarios para ejecutar una llamada de procedimiento remoto.
El stub cliente reúne luego los parámetros y los empaqueta en un mensaje. Esta operación se conoce como reunión de argumentos (parameter marshalling). Después que se ha construido el mensaje, se lo pasa a la capa de transporte para su transmisión (paso 2). En un sistema LAN con un servicio sin conexiones, la entidad de transporte probablemente sólo le agrega al mensaje un encabezamiento y lo coloca en la subred sin mayor trabajo (paso 3). En una WAN, la transmisión real puede ser más complicada.
Cuando el mensaje llega al servidor, la entidad de transporte lo pasa al stub del servidor (paso 4), que desempaqueta los parámetros. El stub servidor llama luego al procedimiento servidor (paso 5), pasándole los parámetros de manera estándar. El procedimiento servidor no tiene forma de saber que está siendo activado remotamente, debido a que se lo llama desde un procedimiento local que cumple con todas las reglas estándares. Únicamente el stub sabe que está ocurriendo algo particular.
Después que ha completado su trabajo, el procedimiento servidor retorna (paso 6) de la misma forma en que retornan otros procedimientos cuando terminan y, desde luego, puede retornar un resultado a un llamador. El stub servidor empaqueta luego el resultado en un mensaje y lo entrega a la interfaz con transporte (paso 7), posiblemente mediante una llamada al sistema, al igual que en el paso 2. Después que la respuesta retorna a la máquina cliente (paso 8), la misma se entrega al stub cliente (paso 9) que desempaqueta las respuestas. Finalmente, el stub cliente retorna a su llamador, el procedimiento cliente y cualquier valor devuelto por el servidor en el paso 6, se entrega al cliente en el paso 10.
El propósito de todo el mecanismo de la Fig.1 es darle al cliente (procedimiento cliente) la ilusión de que está haciendo una llamada a un procedimiento local. Dado el éxito de la ilusión, ya que el cliente no puede saber que el servidor es remoto, se dice que el mecanismo es transparente. Sin embargo, una inspección más de cerca revela algunas dificultades en alcanzar la total transparencia.
El principal problema ocurre con el paso de parámetros. El paso de enteros, números de coma flotantes y cadenas de caracteres por valor es fácil. El stub cliente simplemente los coloca en el mensaje que viajará a través de la red. En el peor de los casos, puede necesitarse una conversión a algún formato de red estándar pero tales conversiones son parte de la capa de presentación y no afectan la operación de los stubs. El paso de estructuras, registros o matrices de esos tipos es igualmente directo.
El inconveniente surge cuando el lenguaje permite el paso de parámetros por referencia, más que por valor. Para un llamado local, normalmente se le pasa al procedimiento llamado un puntero (la dirección del parámetro) y el procedimiento llamado sabe que se está tratando con un parámetro por referencia, así que puede seguir el puntero para acceder al parámetro propiamente dicho, es decir, a los valores que le interesan. Esta estrategia falla completamente para una llamada remota. Cuando el compilador estándar produce el código para el servidor, no sabe nada sobre las RPCs y genera las instrucciones usuales para el seguimiento de punteros. Desde luego, el objeto apuntado ni siquiera está en la máquina del servidor, y aún si lo estuviera, podría no tener la misma dirección que tiene en la máquina del cliente. Como resultado, cuando el servidor intenta usar un parámetro por referencia, obtiene un valor equivocado y el cálculo falla.
Una posible solución es reemplazar el mecanismo de llamadas por referencia por el de llamadas tipos copie/restaure. Con copie/restaure, el stub cliente ubica el ítem apuntado y lo pasa al stub servidor, quien lo coloca en algún lugar de memoria y pasa un puntero al procedimiento servidor. El servidor puede luego acceder a los datos de manera usual. Cuando el procedimiento servidor retorna el control al stub, éste envía de regreso el ítem de datos (posiblemente modificado) al stub cliente, quien lo usa para sobreescribir los valores apuntados en el parámetro por referencia original.
program test(output);
var a:integer;
procedure doubleincr(var x, y:integer)
begin
x := x+1;
vy := y+1;
end;
begin
a := 0; {programa
principal}
doubleincr(a,a);
writeln(a)
end.
Fig. 2. Si el procedimiento doubleinc se ejecuta remotamente, el programa falla.
Aunque el mecanismo copie/restaure trabaja frecuentemente, puede fallar en ciertas situaciones patológicas. Consideremos, por ejemplo, el programa de la Fig. 2. Cuando este programa corre localmente, ambos parámetros en la llamada a doubleinc son apuntados por a, que sufre un incremento doble. Se imprime el número 2. Ahora observemos qué sucede si doubleinc es llamado como un procedimiento remoto usando copie/restaure. El stub cliente procesa cada parámetro separadamente, así que envía dos copias de a al stub servidor. El procedimiento servidor incrementa cada copia una vez y ambas son pasadas de regreso al stub cliente, que sencillamente las restaura. Primero a se restaura en 1 y luego se restaura en 1 nuevamente. En consecuencia, el valor final es 1 en lugar de 2, dando una respuesta incorrecta.
Los punteros dan problemas similares a los parámetros por referencia. Los mismos son especialmente molestos si apuntan el medio de listas complejas, gráficos o estructuras de registros variables. Los parámetros que identifican procedimientos o funciones también son difíciles de manejar, si bien el stub servidor puede crear procedimientos locales a la máquina del servidor que invoquen RPCs inversas a los procedimientos sobre la máquina del cliente especificados en los parámetros. Algunos sistemas de RPC evitan todo el problema prohibiendo el uso de parámetros por referencia y/o punteros en las llamadas remotas. Tal decisión hace más fácil la implementación, pero rompe la transparencia debido a que las reglas para llamadas locales y remotas son diferentes.
Trasladémonos ahora desde el paso de parámetros a otra consideración de implementación: ¿cómo sabe el stub cliente a quién llamar para localizar el procedimiento que necesita? En redes con servicios orientados a conexiones tradicionales las sesiones se establecen entre SSAPs, cada una de las cuales tiene un número de identificación fijo. Para las RPCs se necesita un esquema más simple y aún más dinámico.
Bissel y Nelson han descrito un esquema que comprende no sólo a clientes y servidores sino también a una clase especializada de base de datos. En su método, que se ilustra en la Fig. 3, cuando arranca un servidor, el mismo se registra en el sistema de base de datos, enviando un mensaje que contiene su nombre (cadena ASCII), su dirección de red (por ejemplo, un NSAP, TSAP o SSAP) y un identificador único (por ejemplo, un número aleatorio de 32 bits). Esta registración se efectúa mediante la llamada a un procedimiento export(), que es manejado por el stub (pasos 1 y 2).
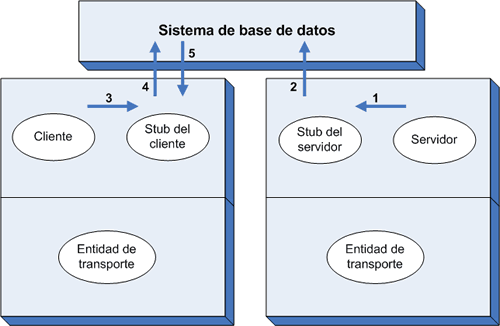
Fig. 3. El vínculo cliente-servidor se hace a través de una base de datos.
Más tarde, cuando el cliente hace su primera llamada (paso 3) y su stub se enfrenta al problema de ubicar el servidor, el stub envía al sistema de base de datos (paso 4) el nombre del servidor, en ASCII. El sistema de base de datos retorna luego la dirección de red del servidor y el identificador único (paso 5). Este proceso se conoce con el nombre de binding. De aquí en más, el stub sabe cómo ubicar el servidor, de manera que no se requiere el proceso binding en las llamadas subsiguientes.
El identificador único de 32 bits se incluye en cada RPC. El mismo es utilizado por la entidad de transporte en la máquina del servidor para indicar a cuál de los varios stubs servidores darle el mensaje entrante. Además tiene otro rol; si el servidor colapsa y rearranca, el servicio se registra nuevamente en la base de datos usando un nuevo identificador único. El intento de los clientes por comunicarse con él usando el identificador único anterior fallará, haciéndoles notar el desperfecto y forzando a un nuevo binding.
Otra exigencia de implementación clave es el protocolo usado. En el caso más simple, el protocolo RPC puede constar de dos mensajes: una solicitud y una réplica (request-reply). Tanto la solicitud como la réplica contienen un número único identificando al servidor, un identificador de transacción y los parámetros. Cuando envía una solicitud, el stub cliente (en algunos sistemas) puede inicializar un temporizador. Si el mismo finaliza su período antes que retorne la respuesta, el stub puede interrogar al servidor para ver si ha llegado la solicitud. En caso negativo, puede retransmitirla. El propósito del identificador de transacción es permitir que el servidor reconozca y rechace solicitudes duplicadas. Téngase en cuenta que el reconocimiento de solicitudes duplicadas sólo es posible si el servidor mantiene la pista de los identificadores más recientes de cada cliente.
Un criterio final de implementación es el manejo de excepciones. A diferencia de las llamadas a procedimientos locales, donde nada puede ir mal, muchas cosas pueden ir mal con una RPC. Por ejemplo, el servidor podría estar fuera de servicio. Si el lenguaje de programación lo permite, la ocurrencia de un error en la RPC no debería darle el control al que iniciara el llamado, sino que podría provocar una excepción a ser manejada por el administrador de excepciones. El diseño de un mecanismo de excepciones depende del lenguaje pero en cualquier caso es necesario prever un método para distinguir las llamadas exitosas de las fallidas.