También, a diferencia de los procesos locales, las llamadas a procedimientos remotos están sujetas a pérdidas de mensajes, caídas del servidor y de los clientes. Esos efectos influyen en la semántica de las RPCs y en el objetivo de hacerlas transparentes. En esta sección analizaremos los problemas ocasionados por las caídas del servidor; en la siguiente examinaremos las caídas del cliente.
La operación normal del protocolo de RPC se muestra en la Fig. 4(a). Sin embargo, consideremos qué sucede si el servidor se cae después de haber iniciado la resolución de la solicitud pero antes de enviar la respuesta. Hay, por lo menos, tres posible maneras de programar el stub cliente para enfrentar esta solución:
- Sólo colgarse esperando una respuesta que no vendrá.
- Esperar por el vencimiento del temporizador y provocar un mensaje de excepción o un reporte de falla al cliente.
- Esperar por el vencimiento del temporizador y retransmitir la solicitud.
El primer enfoque es similar a lo que sucede cuando un programa llama a un procedimiento local conteniendo un loop infinito. No se utiliza ningún temporizador localmente y el procedimiento nunca retorna. Se requiere intervención manual para abortar el programa. La segunda postura para manejar las caídas del servidor es hacer que venza un temporizador en el stub cliente y se provoque una excepción (si el lenguaje de programación soporta excepciones) o reporte un error en otros casos. Este método es análogo a lo que sucede si el procedimiento llamado obtiene un error de protección de memoria o intenta dividir por cero. En tal caso, si hay habilitado un administrador apropiado, la excepción será capturada y procesada; en caso contrario, el programa abortará.
La tercera postura para manejar las caídas del servidor es hacer que venza un temporizador en el stub cliente y retransmitir la solicitud. Dado que el servidor se registrará después de la caída con un nuevo identificador único en la base de datos del sistema, la retransmisión será rechazada por la entidad de transporte sobre la máquina del servidor cuando vea al antiguo identificador, ahora válido. Si la entidad de transporte envía una respuesta de error, el stub cliente puede, o bien abandonar (esencialmente el enfoque anterior), o bien hacer un rebind e intentarlo nuevamente. Si se hace esto último y el stub cliente repite la llamada, resulta posible que la operación sea llevada a cabo dos veces, como se muestra en la Fig. 4(b). De hecho, podemos conseguir la ejecución repetida aún sin caídas si la respuesta se pierde y permitirle al stub cliente intentarlo nuevamente.
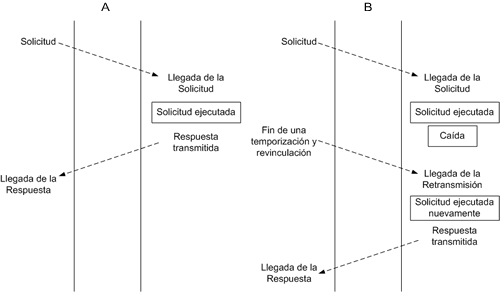
Fig. 4. (A) RPC ordinario de dos mensajes. (B) RPC con una caída del servidor y una temporización del cliente.
Si se acepta o no la ejecución repetida depende de la clase de operación que se está ejecutando. Si la operación consiste en la lectura del bloque 4 de un archivo, no hay ningún daño si se repite mil veces. Cada vez produce el mismo resultado y no hay efectos colaterales. En cambio, si la operación consiste en el agregado de un bloque al final de un archivo, importa mucho cuántas veces se ejecuta la operación.
Cuando las operaciones pueden repetirse sin ningún daño se dicen que son idempotentes. Si todas las operaciones pudieran proyectarse en una forma idempotente, obviamente la tercer postura sería la mejor. Desafortunadamente, algunas operaciones son inherentemente no-idempotentes (por ejemplo la transferencia de una cuenta bancaria a otra). Como consecuencia de ello, la semántica exacta de los sistemas de llamada a procedimiento remoto puede clasificarse de varias maneras.
La clase más deseable se conoce como exactamente una vez, donde cada llamada se lleva a cabo exactamente una vez (ni más ni menos). Esta meta resulta difícil de alcanzar debido a que después de una caída del servidor no siempre resulta posible si la operación fue ejecutada o no, hecho que puede resultar crítico en una fábrica o cadena de producción controlada por computadora, por ejemplo.
Se logra una forma más débil de la semántica “exactamente una vez” si el lenguaje de programación soporta el manejo de excepciones. En esta variante, si una llamada retorna normalmente, significa que no ha ocurrido ninguna anormalidad y que la operación ha sido ejecutada exactamente una vez. Si el servidor se cae o si se detecta otro error serio, la llamada no devuelve nada. En su lugar, se produce una excepción y se invoca el administrador apropiado. Con esa semántica, los procedimientos clientes no tienen que ser programados para enfrentarse con los errores sino que lo hacen los administradores de excepciones.
Una segunda clase es la denominada a lo sumo una vez en la que, cuando se utiliza, el control siempre retorna al llamador. Si todo fue correcto, la operación se ejecuta exactamente una vez. Sin embargo, si se detecta una caída del servidor, el stub cliente renuncia y retorna un código de error sin llevar a cabo ningún intento de retransmisión. En este caso, el cliente sabe que la operación ha sido ejecutada cero o una vez, pero no más; la posterior recuperación es una cuestión del cliente.
Una tercera clase se conoce como al menos una vez. El stub cliente permanece intentando una y otra vez hasta que consigue una respuesta adecuada. Cuando el control retorna al llamador, éste sabe que la operación ha sido ejecutada una o más veces. Para operaciones idempotentes esta situación es la ideal. Para operaciones no-idempotentes, podemos distinguir distintas variantes. Probablemente, la más útil de ellas es la que garantiza que el resultado retornado es el resultado de la última operación, nunca el de las anteriores. Si el stub cliente usa un identificador de transacción distinto en cada retransmisión, será posible determinar fácilmente qué respuestas pertenecen a qué solicitudes y así filtrar todas excepto la última. Esta semántica es conocida como la última de varias.
En resumen, el objetivo de una semántica RPC totalmente transparente es considerablemente complicado por la posibilidad de caídas que afecten al servidor pero no al cliente. En un sistema de procesador único, esto no puede darse debido a que un crash que destruye al servidor también arrastra al cliente y a todo el sistema con ellos.